OpenConfig and IETF YANG Models: Can they converge?
imported Tech · IETF · OpenConfig · YANG
At IETF96 in Berlin, the chairs of the NETMOD working group, and Operations Area Director (Benoit Claise) published a statement to say “Models need not, and SHOULD NOT, be structured to include nodes/leaves to indicate applied configuration”. Now, this might seem a pretty innocuous statement, but it actually has a number of implications for the data models for network configuration and state that are being produced in the industry.
What is applied configuration?
The first question to an uninitiated reader might be, what is “applied configuration”? It’s not a term that has been in the common network nomenclature - and hence does need some further explanation. To define it, we need to look at the way that configuration is changed on a network element.
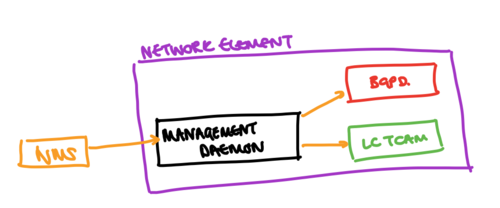
In general, when a configuration is changed, the entity (be it human, or a machine) that is interacting with the device interacts with a management daemon that is responsible for running the interface that the change is being made through. This management daemon is then responsible for updating the various elements of the system (either directly, or through an interim configuration database). A basic overview of this separation is shown in the diagram above (which we’ll refer to later).
This separation means that there can be a difference between what the operator wanted the system to be running (the intended state of the system), and what the system is actually running (the applied state). The difference might be for a number of reasons, for example:
- There may be some contention in the CPU of the network element such that the management daemon shown is not able to communicate configuration changes to the BGPd process.
- Some elements of the system might have bottlenecks in their programming time - for example, the green linecard TCAM (LC TCAM) might have a specific rate at which ACL entries can be installed.
- A large number of configuration changes may be queued by the management daemon to be applied to other elements in the system, such that a particular change in value is queued behind others in the system.
- Dependencies for the configuration to become applied are not present (e.g., the linecard that a referenced interface is on is not actually installed).
Operationally, it’s useful to be able to determine what the system is doing - for example, if I am expecting that packets are filtered at the edge with an iACL, then it’s useful to know that iACL has actually been programmed by the system into the linecard.
When we’re thinking about humans changing configuration of the network, there are some systems that we might say don’t really have the concept of some of the issues that we’re discussing here.
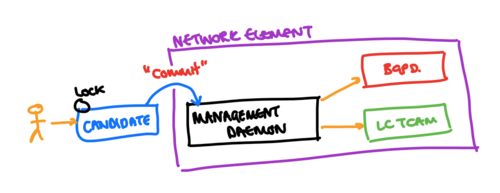
In a system such as the one shown above, then a “candidate” configuration is edited - usually by simply opening an edit session on the configuration. This may create some form of lock (rate-limiting the number of changes that the system may apply). This candidate configuration is then applied using some form of “commit” operation - which may also involve communicating the change to the daemons responsible (especially if those daemons are partially responsible for validation of the changes in intended state that are being communicated). In theory, such systems would not have a view of an “applied” configuration, because one would expect that the “commit” operation ensures that the configuration change has been applied.
However, such a simplification isn’t robust - since a number of the reasons for the box having an intended configuration that differs from that which is applied still exist - for example, the lack of presence of a particular hardware element, or the limited programming bandwidth of a particular hardware element.
In addition, this heavy-weight commit process means that the rate of change on the device is limited. For humans, this perhaps does not matter (although some vendors have implemented light-weight commit systems to overcome this issue, since commits could take many minutes) - but when a machine might be making changes, then creating locks and heavy-weight commit logic is something that may hugely increase the complexity of the overall NMS and network element system, especially where there are multiple writers to an individual network element.
An Overview of an Network Management Architecture
OpenConfig aims to support a network management architecture whereby there can be rapid changes made to an individual network element, by multiple writing systems. Such a system makes use of the fact that the intended and applied configurations can be differentiated from one another.
To understand this, let’s talk through a basic work-flow of how a single writer might make a change to the state of the device.

- The NMS comes online and subscribes to the parameters of the system that it is interested in. Let’s say that this NMS is specifically an ACL writer, and doesn’t care about any of the other configuration. In this case, it might use the openconfig-acl model to subscribe to
/acl. Using an RPC that implements the generic OpenConfig RPC specification it can choose how it wants this subscription to occur - for example, asking for a subscription with asample-intervalof 0, such that it receives updates only when the values within the path it is interested in change. At this point, the network element sends updates to the NMS as requested, informing it of changes in the values that it has indicated interest in. - The NMS then wishes to make some change to the configuration of the device - it stages a number of changes together, and sends then using a
SetRPC call. This RPC can specifically be requested to be transactional, such that the changes in theSetmessage share fate, or they can be individual. No lock is requested by the NMS, since it will not address the network element through multiple messages - and rather has already constructed a “candidate” configuration itself. As the network element receives the update to the intended configuration from the NMS, it also pushes a telemetry update back to it, to indicate that the intended values have changed. - After some processing, the device updates the actual configured value - e.g., the TCAM on the linecard is programmed with a new ACL entry - and then pushes a telemetry update to the system to indicate that it has actually been applied. At this point, the listening NMS system can validate that the change it has made has actually been applied by the system.
In this case, the presence of applied configuration is fundamental to ensuring that the NMS can actually validate that the system is running the configuration that it pushed to it. The Set operation can remain relatively light-weight, meaning that it is possible for other systems to make changes to the intended state of the system. This has particular advantages when one considers locking granularity - the OpenConfig model only implies a lock that is held during processing of an individual Set operation; alternate models that can allow candidate configurations to edit may have relatively long lived global locks, or a complex series of locks on different parts of the data tree to ensure consistency of a candidate configuration when it is actually committed.
This architecture also allows for two systems that are writing the same set of configuration to remain in synchronisation about what configuration is actually running on the network.
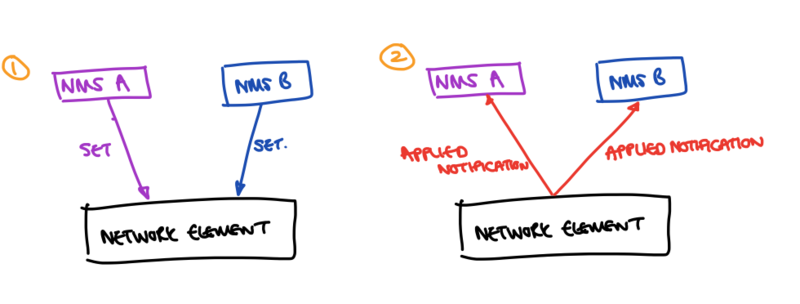
In the above scenario - we have two NMSes, A and B, writing to the same network element. It may be that they are writing the same paths, or different sets, but each within the other’s “interest domain”. If both A and B do Set operations towards the NMS, then there is a problem of re-synchronising the view of the data tree that A or B used such that subsequent data instances that are generated can be validated against the expected config of the network element (e.g., to validate leafrefs, or determine whether elements of a service need to be configured). In this case, we care about what the network element is actually running. Through subscribing directly to the applied configuration, as soon as the network element has updated a value, then a telemetry notification is sent to both NMSes, such that it is possible for NMS A and NMS B to maintain an eventually consistent view of the configuration of the device, without needing to poll it directly.
The advantage of using the applied configuration over the intended in this case, is that if configuration has been set by one NMS that for some reason does not become applied, other systems are able to determine that the device isn’t actually running that configuration - and therefore attempt to set it how they see fit, to make their required change.
What does this have to do with model structure?
To support the above use cases, we need to make both the intended and applied configuration of the network element addressable to external clients. Additionally, we need to make it simple for those systems to be able to determine how the intended configuration relates to the applied - since they will be writing to the intended, and potentially then observing the value of the applied.
OpenConfig’s solution for this is to utilise the structure of the model to be able to indicate these things. For example, if we have an administrative state of an interface, OpenConfig will create a particular container for the interface, and within it have a config branch which contains the configurable values, and a state branch which contains the state that relates to that entity - including the applied config (which is, after all, state). Along with the applied config are the values that are derived from how that entity interacts with other elements - in our interface example, the counters that relate to it, the actual operational status of the interface, etc.
The OpenConfig model layout therefore has a structure similar to the following:
interfaces
interface[name=eth0]
config
admin-status: up/shutdown
state
admin-status: up/shutdown
operational-status: up/down
counters
pkts-in: integer
...
This means that we have a path of /interfaces/interface[name=eth0]/config/admin-status which can be written to, setting the intended state of that interface. The actual running admin-status (i.e., whether it is shutdown or not) can be found using the /interfaces/interface[name=eth0]/state/admin-status value. Clearly, this is very easy to relate to the intended value, since one simply substitutes the “config” container that surrounds the leaf with the “state” one.
Additionally, if an NMS were then interested in all the operational state that relates to this interface it can retrieve the contents of the “state” container under the interface, where all state that relates to the interface it configured is located.
This layout is consistent throughout the models - i.e., it’s possible to guarantee that there is a “state” leaf for each “config” leaf, and that the state that is related to that entity can be directly retrieved by using the partner “state” container. OC models are validated using tooling that ensures that this rule is consistent, such that those interpreting data coming from network elements using this schema can rely on it - and subscriptions for particular paths can consistently get the right thing (for example, subscribing to /interfaces/interface[name=eth0]//state yields all state for each entity associated with an interface).
Where does this leave the IETF?
The IETF NETMOD working group has essentially rejected the approach that OpenConfig proposed in December 2014, leaving it with a number of questions to address:
- How will applied configuration actually be represented? OpenConfig’s approach works with a protocol that presents a single view of the data, as well as those that want to provide some divisions of the data tree (if leaves were annotated they could be presented in different “views”). NETMOD would like to pursue a solution that does not support single-view implementations - and hence uses the NETCONF “data store” concept for modelling applied configuration. At the current time, whilst there are abstract proposals for how this would look, there is no running code that represents this.
- How usable will models that the IETF produces actually be? Currently, the IETF BGP and MPLS-TE models adopt the convention that OpenConfig uses, but other than this, there is little consistency as to how state and configuration data should be represented in their models. There is a real danger for the IETF that it produces models that have no consistency between them - this means trading the Cisco/Juniper/ALU config differences for a set of differences between the way that the model that you configure your IGP works, and then the one that you configure MPLS or BGP with work. The IETF’s allergy to architecture and having a top-level view of what to build and how to build it means that this consistency is very difficult to achieve.
- When will IETF models actually be published? The decision NETMOD has made, along with there being no clear solution for the representation of applied config in IETF models has further implications. Vendors are already implementing OpenConfig - and for those models that are also IETF models, they now have some duplication of development efforts if they want to support IETF models too. Additionally, new efforts in the IETF are required to refactor those models that adopted the OpenConfig convention (given that some of these are actually written by OpenConfig authors, then there is the question of who does this work). Building a coherent set of models that allow operators to configure real functions on their network is likely to need significant efforts, has taken some time already.
Where does this leave OpenConfig?
OpenConfig’s approach to interaction with the IETF after the first 6 months of the discussion (which is just reaching 18 months old) was to suggest that operational experience of the approach that was suggested is crucial. This experience allows us to determine the solution’s efficacy, and work through any issues that become evident. This iteration process is invaluable - since it means that both the network elements and NMS implementations can really be scoped out. Since that suggestion was made back at IETF 94, multiple NMS and vendor implementations have emerged - such that we should be able to report back on progress in the relatively near future.
It does mean, however, that OpenConfig is unlikely - for some time at least - to converge with the IETF models. The IETF will need to solve the issues above, and negatively impacting the industry building knowledge of model-driven interaction with network devices, and the complexities of supporting non-native schemas appears a huge downside to “waiting for alignment”.